Envoy 的运作原理
Envoy 本质上就是一个 3/4/7 层代理,收到下游(Downstream)的请求,转发到通过负载均衡算法选择的一个上游(Upstream)服务主机(Host),将上游响应传回下游。
Envoy 通过避免将请求转发到不健康的上游服务主机(Host)来保障服务的稳定性。
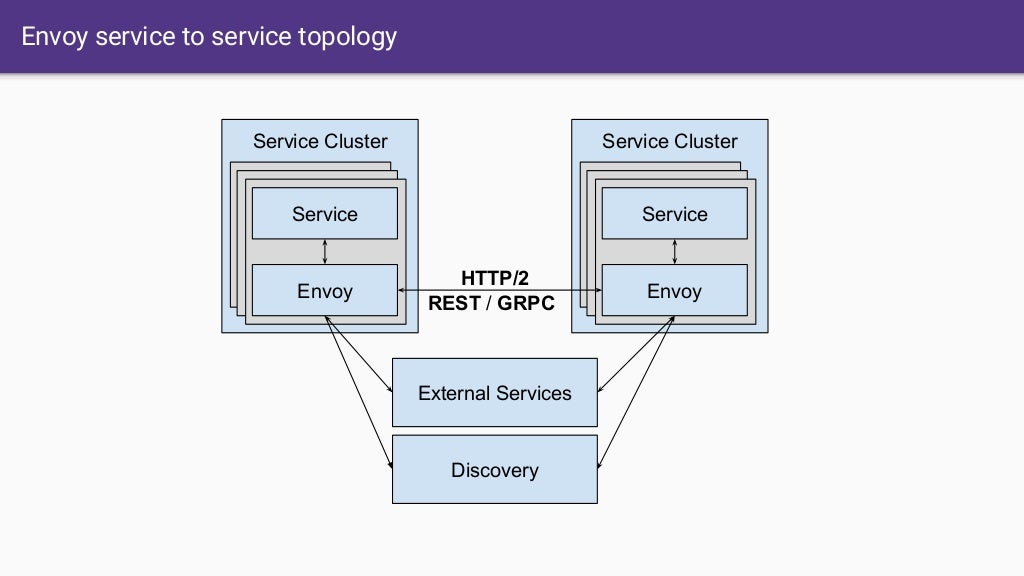
通常用于服务间通信,典型的 Envoy 运行方式就是 服务网格:
Envoy 的 Resiliency Features
Resiliency Features:
- Timeouts
- 请求处理时间超过阈值后取消请求
- Retries
- 重试处理出错的请求
- Circuit Breaking
- 限制到上游集群(Upstream Cluster)的并发连接、请求数
- Rate Limiting
- 限制下游(Downstream)的请求速率
- Health Checking
- 主动检查上游集群(Upstream Cluster)的健康度
- Outlier Detection
- 被动检查上游集群(Upstream Cluster)的健康度
- Fault Injection
- 通过注入故障来测试服务的稳定性
其中
Circuit Breaking
静态地为上游服务的处理能力设定上限,丢弃超过上游服务处理能力的请求。
Health Checking 、Outlier Detection
动态地检测服务主机(Host)的健康状况,通过将不健康的服务主机(Host)驱逐一段时间来复原系统。
Fault Injection
通过模拟请求失败或变慢来测试系统的复原能力。
Envoy 怎样实现熔断
当调用的上游(Upstream)服务运行状态良好时,请求失败是非常罕见的,通过运用
Retries pattern 来重试失败的请求,可以提高服务的容错性、健壮性。
当调用的上游(Upstream)服务运行状态异常时,请求失败会大量出现,通过运用
Circuit breaker pattern 来避免发起有很大机率会失败的请求,可以释放系统压力、避免“雪崩效应”。
熔断的核心是一个状态机

包含以下状态:
- Closed
熔断器关闭状态
一段时间内,调用失败次数积累到了阈值(或一定比例)则打开熔断器
- Open
熔断器打开状态
此时对上游(Upstream)的调用直接返回错误,不会真的发起调用,同时开启一个定时器,时长通常为平均故障处理时间(
MTTR),定时器触发后进入半熔断状态- Half-Open
半熔断状态
允许定量的服务请求通过,调用成功次数积累到了阈值(或一定比例)则关闭熔断器,否则回到熔断器打开状态。
Envoy 的 Circuit Breaking 跟熔断完全是两码事,Envoy 主要是通过 Outlier Detection 来实现熔断。
一方面,通过对 Envoy 的 Timeouts 、Retries 、Circuit Breaking、Rate Limiting 合理配置来尽量保障上游(Upstream)服务的稳定运行;另一方面,一旦通过 Health Checking、Outlier Detection 检测到上游(Upstream)服务主机(Host)异常,就会进入熔断状态。
上游(Upstream)服务主机(Host)进入熔断状态后,一段时间内 Envoy 不会往它调度请求,可以减少它对整体服务质量的影响,手动或自动修复故障后重新加入到集群(Cluster)中来,继续提供服务。
Envoy 配置要点
-
调用链越深,其超时值必须越小。
其值应该处于统计出的 99.x 分位值与调用方最大容忍时间之间。
接口响应延迟差异太大的情况下,应该按接口路由分别设置超时值。
如:
"timeout_ms": 100
-
在 Timeouts(超时)时间内可能会发生多次 Retries (重试)。
冥等性的接口才应该进行 Retries 。不应该重试熔断的请求,即从可重试错误码中排除熔断错误码。
通过 Circuit breakers 的 max_retries 来限制到该集群(Cluster)的最大并发重试数。
如:
{ "retry_on": "gateway-error,connect-failure,refused-stream", "num_retries": 1 } -
它不是我们常识中的熔断。
它限制当前 Envoy 往 Cluster 发起的最大并发连接、请求、重试数。
设置超过物理上限的值是没有意义的,相当于禁用了 Circuit Breaking 。
最好是根据统计出的高峰期往 Cluster 发起的并发连接、请求数进行设置。
如:
"circuit_breakers": { "default": { "max_connections": 10000, "max_pending_requests": 10000, "max_requests": 10000, "max_retries": 3 }, "high": { "max_connections": 10000, "max_pending_requests": 10000, "max_requests": 10000, "max_retries": 3 } }
-
一般根据请求发起方(Downstream)的特征模式来设定限速值,如:IP、HTTP 头。
对于需要限速的请求会同步发起一次到限速服务的 Grpc 调用。
停掉限速服务即可关闭限速功能,可以做为一种服务降级手段。
-
它是主动健康检查(Active health checking),可以和 被动健康检查 同时启用。
一般跟服务发现(Service Discovery)一起用。
可用于实现服务(Service)主机(Host)的优雅退出(Gracefully Shutdown)。
健康检测间隔 应该适当设置大一些,以免发起的健康检查请求过多。
-
实现被动健康检查(Passive health checking),可以和 主动健康检查 同时启用。
它才是真正的熔断。
默认 5 个连续的 5XX 错误就会触发熔断,应该根据服务的请求量来确实合适的值。
驱逐时间默认为 30 秒,最好设置为服务的平均故障处理时间(
MTTR)。如:
{ "consecutive_5xx": 5, "consecutive_gateway_failure": 5, "interval_ms": 5000, "base_ejection_time_ms": 30000, "max_ejection_percent": 100, "enforcing_consecutive_5xx": 10, "enforcing_consecutive_gateway_failure": 10, "enforcing_success_rate": 0 }
从熔断到降级
熔断和降级是非常容易混淆的概念,它们往往同时出现,在一定程度上可以认为熔断是一种自适应式的降级。
熔断、降级的场景
去饭店聚餐
A 到了,服务员给倒了热茶,喝了一口,烫,放下,过一会喝,还是烫,放下,继续等冷了再喝。
B 到了,服务员给倒了热茶,烫,放下,服务员过来给换了温水,喝一口,还行。
C 到了,服务员给倒了温水,喝一口,还行。
A 遇到的是熔断,B 遇到熔断后触发的降级,C 遇到的是提前安排的降级。
熔断、降级的特点
- 熔断和降级都意味着整体服务可用,但部分功能不可用,降低了用户体验
- 熔断是避免最坏结果出现的极端手段,简单粗暴
- 降级是避免最坏结果出现的预防机制,弃车保帅
- 熔断一般是由于检测到某个上游服务异常而自动触发的局部行为
- 降级一般是由于预判到整个系统可能崩溃而提前安排的全局行为
降级的实施步骤
- 根据功能依赖及重要程度确定优先级
- 分为多级,循序渐进式降级
- 确定降级配置下发机制以及触发机制
- 运维平台下发渠道、根据错误码自动触发降级
- 确定降级的处理方式
- 返回默认值、调用替代服务、返回缓存值等
- 在可降级功能的调用入口埋点
- 按下发的配置决定是否真的调用目标服务